[MSSQL] Clustered Index, Non-Clustered Index
데이터베이스는 머신의 하드디스크 혹은 SSD에 위치한다.
디스크의 헤드가 도는 속도는 느리다. 양보해서 SSD라 할지라도,
테이블의 레코드의 양이 많아지면 많아질수록 원하는 특정 레코드에 대한 쿼리는 점차 부담스러운 일이 된다.
이때에 인덱스를 적절하게 활용하면 성능을 개선시킬 수 있다.
SQL Server에서의 인덱스 방식은 주로 두가지 방식에 대해서 이야기한다.
Clustered Index와 Non Clustered Index.
두가지 인덱싱 방식은 매우 유사하면서도, 차이를 보인다.
Clustered Index
이름에서 알 수 있듯 테이블과 인덱스가 결합되며, 인접한 인덱스의 레코드가 결합되는 방식이다.
(특정 키값을 컬럼에 가진 레코드를 찾을때 결합된 인덱스가 내부에 있고 이를 이용한다고 생각하자.)
레코드의 순서 자체를 아예 인덱스로 설정된 컬럼의 순서대로 정렬하는 방식이다.
그래서 테이블당 단 하나만 생성할 수 있다.
또한 컬럼의 값이 중첩되게 해서는 안된다.
당연하지 않은가? 테이블 자체를 정렬시킬건데 기준이 두개 이상이면 곤란하다.
데이터를 정렬을 완료했다면 이후,
Clustered Index에 레코드로 직접적으로 향하는 주소를 기록해두지 않는다.
대신 페이지라고 불리는 일종의 메모리 블럭의 단위를 참조하도록 해당 주소를 기록해둔다.
쿼리를 날리면 그 페이지 내부에서 서칭해 나간다.


비유를 하자면 마치 사전과 유사하게 동작 한다고 할 수 있다.
사전은 가나다순, ABC순으로 정렬되어 있다.
예를 들어 사전을 사용할때 CARTIER 라는 단어를 찾는다고 해보자.
그럼 누구나 당연하게도 C로 시작하는 페이지에서 먼저 찾을 것이다.
C로 시작하는 단어는 굉장히 많다.
그러니 또 내부에서 C로 시작하는 단어들이 모인 페이지에서 또 다시 A로 시작하는
단어가 모인 페이지로, 그다음은 R, 그다음은 T 이런 방식이다.
컬럼을 Primary Key로 설정하고, 아무런 옵션을 주지 않으면, 자동적으로
Clustered Index로 설정된다.
Non Clustered Index
테이블당 여러개를 생성할 수 있다.
Clustered Index와 마찬가지로 레코드 서칭시 트리구조를 사용한다는 점은 같다.
허나, Clustered Index 처럼 테이블 자체를 인덱스로 설정된 컬럼순으로 정렬하지는 않는다.
그럼 테이블이 정렬되어 있지도 않은데 어떻게 트리구조를 사용하냐?
Non Clustered Index는 테이블을 정렬시키는 것이 아니라, 별도로 정렬된 트리를 하나 만든다.

그리고 만든 트리의 터미널 노드에 실제 데이터가 있는 곳의 물리주소를 페이지의 주소와 오프셋의 형태로 기록해둔다.
컬럼을 PRIMARY KEY로 설정하고, 아무런 옵션을 주지 않으면, 자동적으로
Clustered Index로 설정된다고했다.
마찬가지로 만약 컬럼을 UNIQUE로 설정 하고, 다른 옵션을 주지 않으면,
Non Clustered Index가 자동적으로 설정된다.
Clustered Index VS Non Clustered Index
SELECT
Clustered Index는 SELECT에서 Non Clustered Index에 비해 상당히 우수한 성능을 발휘한다.
Non Clustered Index 또한 정렬된 트리를 가지고 있다.
성능의 차이는 나지 않을 것 처럼 보인다.
단순히 키 값과 딱 일치하는 값 하나만 찾는다면, 거의 차이가 나지 않는다.
허나 키 값을 범위로 지정했을때가 차이가 난다.
만약 키 값이 1 ~ 5000 까지 인 레코드를 찾으라고 쿼리를 날리면 어떻게 될까?
Clustered Index는 거의 한번만 트리를 타면 된다.
(서로 다른 블럭에 위치해 있다면 뭐 몇번 더 탈 가능성은 있다.)
Non Clustered Index는 5000번 트리를 타야한다.
왜? 실제 데이터가 정렬된게 아니라는 데에서 오는 한계이다.
INSERT, UPDATE, DELETE
INSERT, UPDATE, DELETE 시에는 Clustered Index가 불리하다.
왜냐하면 테이블 자체가 정렬되어 있기 때문에,
순서에 맞게 집어 넣기 위한 작업이 필요하다.
이때 레코드가 들어가야하는 페이지에 충분히 공간이 있다면 다행이겠지만,
만약 페이지가 분할 되어야 한다면 이때 피곤해지는 거다.
충분히 생각해볼만 한 문제이다.
반면 Non Clustered Index는 INSERT, UPDATE, DELETE에서 상황이 괜찮다.
물론 트리에 순서에 맞게 집어 넣고 업데이트 하는 작업은 똑같이 일어나지만,
테이블의 페이지 분할과 같은 일은 일어나지 않기 때문이다.
Clustered Index + Non Clustered Index
Non Clustered Index는 인덱스 키 값으로 정렬시킨 트리를 만들고, 데이터에는 손대지 않는다.
그리고 실제 데이터의 물리주소는 페이지의 주소와 오프셋으로 표현한다고 했다.Clustered Index는 인덱스 키 값으로 테이블 자체를 정렬시키고, 정렬 시킨 테이블의 페이지에서 트리를 순회한다.
만약 테이블 내에 Clustered Index와 Non Clustered Index가 같이 있다면?
이때에는, Non Clustered Index가 데이터의 물리주소를 페이지의 주소와 오프셋으로 표현하지 않는다. Clustered Index의 페이지 값을 기록한다.예를 들어 Key1 이 Clustered Index로 설정되어 있고,Key2는 Non Clustered Index로 설정되어 있다.
그리고 아래의 쿼리를 실행한다고 하자.SELECT * FROM MyTable WHERE Key2 = 'Ramsey'이때에 우선 Non Clustered Index를 통해 Ramsey라는 이름을 가지는 레코드를 찾는다. 그리고
해당 레코드의 Clustered Index인 Key1값을 구한다음, Clustered Index를 사용해
레코드를 찾는다.
Non Clustered Index만 사용했을 때에 존재했던 오프셋으로 표현된 물리주소가 사라지고
Key1의 Value를 구한다음 이를 사용해 Clustered Index를 순회하도록 하는 것이다.
이를 Key Lookup 이라고 한다.
왜 굳이 Key Lookup을 진행할까? SELECT 시의 상황만을 본다면 이것은 명백한 비효율이다.
INSERT,UPDATE,DELETE 시의 상황 때문에 그렇다.
INSERT,UPDATE,DELETE 시 Clustered Index에 의해 테이블은 재정렬 될 것이다.정렬을 진행하였을때 들어가야하는 레코드가 맨 마지막에 들어가야 하는 경우가 아니라면, 당연히 레코드의 물리주소는 이전과 달라진다.
만약, Non Clustered Index 가 레코드의 물리주소를 페이지의 오프셋 형태로 표현하게 된다면,많은 데이터의 물리주소가 변경되었을때에 이에 맞춰 전부다 바꿔줘야 한다.
또한 Non Clustered Index 는 여러개를 가질 수 있다고 하였다.
여러개에 대해서 이 작업이 진행된다면 여러모로 성능적으로 피곤한 일이 될 것이다.
때문에 굳이 Clustered Index의 키를 구한다음 이를 통해 우회하게 되는 것이다.
사용
SSMS를 통해서 확인 해본다.
기본적으로 만들어지는 인덱스를 확인해보자.
CREATE TABLE IdxTestTable
(
MyKey1 NVARCHAR(50) PRIMARY KEY,
MyKey2 NVARCHAR(50) UNIQUE,
Val INT
);
//Primary Key 는 기본적으로 Clustered Index 속성이 지정된다.
//Unique Key 는 기본적으로 Non Clustered Index 속성이 지정된다.EXEC sp_helpindex IdxTestTable
//인덱스를 확인 해본다.
컬럼에 PRIMARY KEY 를 주면 Clustered Index가,
UNIQUE 를 주면 Non Clustered Index가 디폴트로 생성되는 것을 확인된다.
Clustered Key 하나만 사용해본다.
CREATE TABLE IdxTestOnlyClustered
(
MyKey1 NVARCHAR(50) NOT NULL PRIMARY KEY CLUSTERED,
MyVal INT
);
//Primary Key를 설정하면 아무 옵션도 주지 않았을때 Clustered Key 로 설정된다.
//위와 같이 명시해도 관계는 없다.
//물론 NONCLUSTERED 로 명시하면 Non Clustered Key로 동작한다.
Clustered Index를 사용했으므로, 알아서 정렬 되어 있다.
검색을 해보자.
SELECT * FROM IdxTestOnlyClustered WHERE MyKey1 = 'RamseyMoon'
이번에는 Non Clustered Index를 사용해보자.
똑같이 MyKey1에만 Non Clustered Index를 적용한다.
전체 테이블 SELECT 결과는 다음과 같다.

Clustered Index와 달리 테이블은 정렬 되어있지 않다.
이번에는 Index를 사용해서 탐색이 어떻게 이루어지는지 보도록 하자.
SELECT * FROM IdxTestOnlyNonClustered WHERE MyKey1 = 'RamseyMoon'
Index Seek은 Non Clustered Index로 탐색을 한다는 뜻이다.
RID Lookup은 키 검색이후, 데이터 페이지에서 찾아본다는 의미이다.
RID 는 Row ID의 약자이다.
실제 데이터가 어디에 위치하고 있는지를 나타내는 포인터라고 이해하면된다.
Non Clustered Index 는 탐색의 결과 나온 리프 페이지에 실제 저장된 RID가 있다고 했다.
리프페이지를 구하고, 리프페이지 안에 있는 RID를 참조하게 되고, RID Lookup이 발생하는 것이다.
마지막으로 Clustered 와 Non Clustered 두개의 형태 Index 모두 사용해보자.
CREATE TABLE IdxTestBothIdx
(
MyKey1 NVARCHAR(50) NOT NULL PRIMARY KEY CLUSTERED,
MyKey2 NVARCHAR(50) NOT NULL UNIQUE NONCLUSTERED,
Val INT NOT NULL
)
//MyKey1 에 Clustered Index를,
//MyKey2 에 NonClustered Index를 준다.
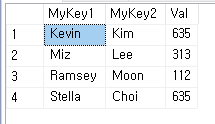
전체 테이블 SELECT 결과 예상한대로 Clustered Index가 적용된 MyKey1 기준으로 정렬됨을 확인할 수 있다.
이제 MyKey1, 즉 Clustered Index 를 사용해 데이터를 탐색해본다.
SELECT * FROM IdxTestBothIdx WHERE MyKey1 = 'Ramsey'
테이블이 MyKey1 기준으로 정렬되어 있으므로 Clustered Index Seek 만 진행하면 된다.
MyKey2, 즉 Non Clustered Index를 사용해 데이터를 탐색해보자.
SELECT * FROM IdxTestBothIdx WHERE MyKey2 = 'Moon'
Non Clustered Index는 Index Seek 을 진행한 다음, RID Seek을 진행하는 것이 아니라,
Key Lookup을 진행한다.
마지막으로 AND를 사용해서 탐색을 한다면?
SELECT * FROM IdxTestBothIdx WHERE MyKey2 = 'Moon' AND MyKey1 = 'Ramsey'
MyKey2 = 'Moon' 이 쿼리문에서는 먼저 왔지만, 어짜피 Clustered Index 가 있으므로 해당 데이터는 중첩되지 않음을
인식하고 Clustered Index Seek을 실행한다.
데이터베이스는 상당히 똑똑하다.