3. 비순차 실행, 슈퍼스칼라 - 2025/08
비순차 실행 (Out-of-Order Execution)
비순차 실행은 명령어 사이의 의존성을 미리 파악해서, 먼저 실행 할 수 있는 명령은 먼저 실행한다는 개념입니다.
비순차 실행은 명령어 수준 병렬성(Instruction Level Parallelism, ILP)을 찾아서 먼저 실행 할 수 있는 명령어는 먼저 실행함으로,
파이프라인에서의 한계를 극복합니다.
다음과 같은 코드가 있고, 프로세서가 이를 순차적으로 실행한다고 하면 어떻게 될까요?
A = S; //(1)
B = A + 1; //(2)
C = X / Y; //(3)
D = Y + 1; //(4)
(2) 에서 B값을 구하기 위해서는 (1)을 실행해서 A의 값을 알아야 합니다. 즉, (2) 는 (1)에게 의존성이 있습니다.
조금 더 나아간 상황에서, S값은 레지스터에 로드되어 있지 않고, X와 Y는 로드되어 있다면 어떨까요?
이 상황에서 순차적으로 명령어를 처리한다면?
(1)에서 F값을 로드하는 시간 만큼 (2),(3),(4) 는 차례대로 처리가 지연 될 수 밖에 없습니다.
(3)와 (4)를 보면 X와 Y 두 오퍼렌드가 필요하지만, 적어도 다른 명령어의 결과를 알아야 하는 의존성이 없습니다.
따라서 (3)과 (4)를 먼저 처리하고, 그 이후 (1),(2) 이 처리가 완료 되더라도,
프로그램의 의미(Semantic)은 차이가 없습니다.
달리 말해, (1)->(2)->(3)->(4)로 처리를 해도, (3)->(4)->(1)->(2) 로 처리를 해도 의미는 조금도 달라지지 않습니다.
(3)과 (4)는 S 값을 로드하는 것과는 아무 관계가 없는데,
프로세서 수준에서 순차적으로 명령을 처리하다보니 파이프라인 스톨이 생기고 성능 손해를 보는 상황입니다.
이러한 점을 개선할 수 있게하는 방식이 비순차 실행 방식입니다.
이런 비순차 실행을 구현하기 위해서는, 명령어에 대한 스케쥴링(Scheduling) 작업이 필요합니다.
(1)과 (2)는 의존성이 있고, (1)과 (3),(4)는 의존성이 없다는 것을 인지하고, 즉시 실행해도 문제가 없는 작업은
앞서 실행할 수 있도록 조율 하는 작업이 필요한 것입니다.
슈퍼스칼라 (Superscalar)
앞선 예제에서 (4)와 (5)는 (1)에 의존성을 가지지 않음과 동시에 서로 의존성이 존재 하지 않습니다.
(4)->(5)로 처리를 해도, (5) -> (4) 로 처리를 해도 역시나 프로그램의 의미를 만족시킵니다.
이렇게 명령어 끼리의 의존성이 없는 상황이 많다라고 하면,
파이프라인 자체를 여러개 둬서 성능을 개선 할 수 있습니다.
이런 방식을 슈퍼 스칼라 라고 합니다.

위 의 예시로 보면, 사이클 마다 두개의 명령어가 투입(Issue) 될 수 있고,
마찬가지로 완료(Graduation, Retirement) 될 수 있습니다.
슈퍼 스칼라 프로세서에 대해서 이야기 할 때,
이렇게 투입/완료가 가능한 명령어 개수에 따라서 N-Issue, N-Wide, N-Way 로 부릅니다.
다만, N개를 항상 투입이 가능하지는 않고, 역시나 Instruction 캐시의 제약과
의존성, 분기문의 제약으로 N개 보다 작은 명령어만 Issue가 가능합니다.
비순차 실행의 구현
어떠한 명령이 실행 가능 한 상황은 어떤 상황일까요?
하드웨어 자원은 사용 가능해야 하고(ALU 연산이라면 ALU를 사용할 순서가 되어야 하는 것)
오퍼렌드는 준비 되어야 할 것입니다. (C = X / Y 에서, X와 Y값 을 알아야 합니다.)
이러한 과정을 구현하기 위해서는 위 두가지 사항이 준비가 되었는지,
지속적으로 확인하고, 실행이 가능한 시점 적절하게 실행 되도록 해야합니다.
여기에서 두가지의 하드웨어 큐 구현이 사용되는데,
Reservation Station(RS) 과 ReOrder Buffer (ROB) 가 그것 입니다.

Reservation Station(RS)
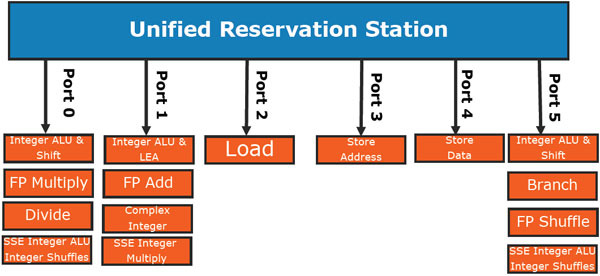
실행가능한 상태를 확인하고 계획하는 작업을 스케쥴링 된다고 합니다.
이러한 하드웨어에서 동적 스케쥴링을 담당하는 장치를 Reservation Station(RS) 이라고 부릅니다.
이 Reservation Station은 큐와 같은 형태로 구현되어 있습니다.
Reservation Station에서 명령어는 자신의 피연산자, 하드웨어 장치가 준비될 때 까지 기다립니다.
앞선 예제를 실행한다고 하면, Decode단계에서 명령어들이 순서대로 RS로 이동하게 됩니다.
(1)은, A값을 기다립니다.
(2)는 역시 A값을 기다립니다.
(3)은 X값을 이미 알고 있으므로 계산 가능합니다.
(4)는 Y값을 이미 알고 있으므로 계산 가능합니다.
(1),(2)는 A값이 준비 될 때까지 지속적으로 감시합니다. 이것을 Wake-up 작업이라고 합니다.
(3),(4) 는 데이터의 의존성이 해결된 상황입니다.
이 때는 하드웨어 장치의 할당을 기다립니다. 하드웨어 자원이 준비 되었다면,
명령어에 대해서 하드웨어 장치를 할당합니다. 이것을 Select 작업이라고 합니다.
ReOrder Buffer(ROB)
ROB 역시 Decode 단계에서 명령어 단위로 하나씩 순서대로 할당 됩니다.
즉, RS의 경우와 마찬가지로 ROB에도 명령어가 하나씩 들어갑니다.
앞선 예제를 보면 RS에 있는 (3),(4) 명령어는 먼저 실행 되었을 것입니다.
분명히 값도 구했을텐데, (3) 과 (4)에서의 계산의 결과가 먼저 적용되었다고 인식할 수 있는 것은 절대 아닙니다.
이렇게 된다면 소프트웨어 수준에서 프로그래머는 매우 혼란스러울 것 입니다.
따라서 계산의 효율성을 높이기 위한 장치가 비순차 실행일 뿐, 소프트웨어 수준에서
계산 결과의 인식 순서는 명령어 순서대로 입니다.
이렇게 외부에서 인식 가능한 값으로 적용이 되는 시점을 Commit 시점이라고 하는데,
이 Commit 시점을 명령어 순서에 맞게 적용시켜주는 장치가 바로 이 ROB 입니다.
즉, (1)->(2)->(3)->(4) 의 순서대로 Commit 되고, 계산이 끝났다고 인식 할 수 있는 것 입니다.
예외에 있어서도 마찬가지 입니다. (3)의 Y가 0 였다고 가정하더라도,
반드시 (2)에서의 B값이 계산 되고나서 예외가 발생 할 것 입니다.
레지스터 리네이밍
레지스터 리네이밍은 가짜 의존성을 없애고, 비순차 실행에서의 효율을 높이기 위한 방법입니다.
ISA에서 사용하는 레지스터는 프로그램 실행시 프로세서간 호환성을 맞추기 위해서 작은 범위로 한정 되어 있습니다.
현대의 프로세서는 ISA의 논리 레지스터의 범위보다 훨씬 더 큰 물리 레지스터 파일(Physical Register File, PRF)을 가지며,
하드웨어 수준에서 이에 대한 접근은 그에대한 오프셋과 같은 형식으로 이루어집니다.
(즉, 하드웨어 수준에서는 PRF[N] 등과 같은 방식으로 접근이 가능 하다는 것.)
달리 말해, 하드웨어 수준에서 이것을 논리 레지스터 -> 물리 레지스터로 매핑을 위한 자원은 충분하고,
이를 통해 명령어 수준에서의 의존성을 피할 수 있습니다.
이 매핑 정보는 레지스터 별칭 테이블 (Register Alias Table, RAT) 에 저장되며,
Decode 작업에서 RS와 ROB로 들어가기 전에 이루어 집니다.
다음의 예를 보겠습니다.
r1 = r0 + 1; //(1)
r2 = r1 + 3; //(2)
r2 = r1 + 4; //(3)
r3 = r2 + 3; //(4)
디코드 단계에서 위의 코드를 다음과 같은 방식으로 미리 바꾼다면,
RS가 의존성이 없다는 것을 더 간단하게 파악할 수 있습니다.
r1 = r0 + 44; //F1 = F0 + 44;
r2 = r1 + 112; //F2 = F1 + 112;
r2 = r1 + 89; //F3 = F1 + 89;
r3 = r2 + 223; //F4 = F3 + 223;
'컴퓨터시스템' 카테고리의 다른 글
| 6. 가상 주소 변환 / TLB (0) | 2025.09.01 |
|---|---|
| 5. 분기 예측 (0) | 2025.09.01 |
| 4. 캐시 메모리 (0) | 2025.08.19 |
| 2. 프로세서 파이프라이닝 (0) | 2025.08.15 |
| 1. 프로세서 인터페이스 ISA (0) | 2025.07.19 |


